
배경
chapter 3까지 공부하면서 회귀모델 두 가지를 공부했다. 하지만 scikit-learn는 아직 써보지 못한 Regressor가 많이 남았다.
다른 회귀모델을 써보면서 직접 점수까지 확인해보기로 했다.

상세
먼저 혼공머신에서 공부한 회귀모델인 선형회귀와 K-최근점 이웃 회귀모델을 가지고 온다.
import pandas as pd
import numpy as np
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,
21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7,
23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5,
27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0,
39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5,
44.0])
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(perch_length, perch_weight
,random_state = 42)
#차원 재배열
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1,1)
print(train_input.shape, test_input.shape)
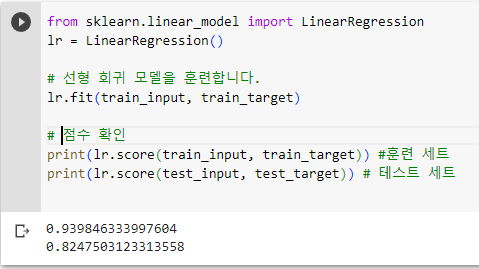
선형회귀보다 아무래도 k최근접 이웃회귀 모델이 좀 더 테스트 성능이 높게 나온다.
다른 회귀모델은 어떨지 코드를 넣어보았다.
랜덤포레스트 회귀모델
# 랜덤포레스트 모델
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor()
rfr.max_depth=5
# 모델을 훈련
rfr.fit(train_input, train_target)
print(rfr.score(train_input, train_target)) #훈련 세트
print(rfr.score(test_input, test_target)) # 테스트 세트
의사결정나무 회귀모델
# 의사결정나무 모델
from sklearn.tree import DecisionTreeRegressor
dtr = DecisionTreeRegressor()
dtr.max_depth=3
# 모델을 훈련
dtr.fit(train_input, train_target)
print(dtr.score(train_input, train_target)) #훈련 세트
print(dtr.score(test_input, test_target)) # 테스트 세트
그런데 코드가 너무 비효율적이고 소수점이 거슬려서 수정하기로 했다.
# 스코어
def score(model):
print(model,'\n', '훈련: ', '{:.4f}'.format(model.score(train_input, train_target)),
'테스트: ','{:.4f}'.format(model.score(test_input, test_target)))
점수를 보여주는 함수를 하나 만들어서 아래와 같이 전체 모델의 성능을 한 눈에 비교해보기로했다.
import pandas as pd
import numpy as np
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,
21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7,
23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5,
27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0,
39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5,
44.0])
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(perch_length, perch_weight
,random_state = 42)
#차원 재배열
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1,1)
#print(train_input.shape, test_input.shape)
# 스코어
def score(model):
print(model,'\n', '훈련: ', '{:.4f}'.format(model.score(train_input, train_target)), '테스트: ', '{:.4f}'.format(model.score(test_input, test_target)))
# k-최근접 이웃 회귀 알고리즘으로 테스트
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor()
knr.n_neighbors = 3
#k-최근접 이웃 회귀모델을 훈련
knr.fit(train_input, train_target)
score(knr)
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
# 선형 회귀 모델을 훈련합니다.
lr.fit(train_input, train_target)
score(lr)
# 의사결정나무 모델
from sklearn.tree import DecisionTreeRegressor
dtr = DecisionTreeRegressor()
dtr.max_depth=3
# 모델을 훈련
dtr.fit(train_input, train_target)
score(dtr)
# 랜덤포레스트 모델
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor()
rfr.max_depth=5
# 모델을 훈련
rfr.fit(train_input, train_target)
score(rfr)결과는 아래와 같다.
KNeighborsRegressor(n_neighbors=3)
훈련: 0.9805 테스트: 0.9746
LinearRegression()
훈련: 0.9398 테스트: 0.8248
DecisionTreeRegressor(max_depth=3)
훈련: 0.9869 테스트: 0.9630
RandomForestRegressor(max_depth=5)
훈련: 0.9892 테스트: 0.9765
두 모델 모두 max_depth를 바꿔서 성능을 바꿔가면서 가장 괜찮게 나오는 하이퍼 파라미터 값을 선택했다.
랜덤포레스트의 경우 실행할 때마다 값이 조금씩 달라지는데 이를 방지하기 위해서는 random_state 메소드도 고정으로 넣어주어야하 한다.
**각 모델에 대한 설명은 추후에 보강하려고 한다. (일단 시간이 없어서 정리만)
** 사실과 다른 내용이 있을 수 있습니다. 언제든지 피드백 부탁드립니다!
반응형
'스터디 > 혼공학습단 10기 - 자바 & 머신러닝' 카테고리의 다른 글
| [혼공학습단] 3주차 - 최적의 에포크값, 내 맘대로 찾아보기 (0) | 2023.07.23 |
|---|---|
| [혼공학습단] - 혼공자바 3주차(7/17 ~ 7/23) (0) | 2023.07.23 |
| [혼공학습단] 3주차 - 로지스틱 회귀를 확실하게 이해해보자! (0) | 2023.07.17 |
| [혼공학습단] 객체지향 프로그래밍을 좀 더 쉽게 이해해보자. (0) | 2023.07.16 |
| [혼공학습단] - 혼공자바 2주차(7/10 ~ 7/16) (0) | 2023.07.16 |




댓글