
기본미션
| 주차 | 진도 | 기본 미션 |
| 2주차 (07/10 ~ 16) |
chapter 03 | Ch.03(03-1) 2번 문제 출력 그래프 인증하기 |
참고로 아래 코드는 train_input, train_target 데이터가 존재하는 가정하에, 작성된 코드이다.
#k-최근접 이웃 회귀 객체를 만듭니다.
knr = KNeighborsRegressor()
# 5에서 45까지 x좌표를 만듭니다.
x = np.arange(5, 45).reshape(-1,1)
# n = 1, 5, 10일때 예측 결과를 그래프로 그립니다.
for n in [1, 5, 10]:
#모델을 훈련합니다.
knr.n_neighbors = n
knr.fit(train_input, train_target)
prediction = knr.predict(x)
#훈련 세트와 예측 결과를 그래프로 그립니다.
plt.scatter(train_input, train_target)
plt.plot(x, prediction)
plt.title('n_neighbors = {}'.format(n))
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
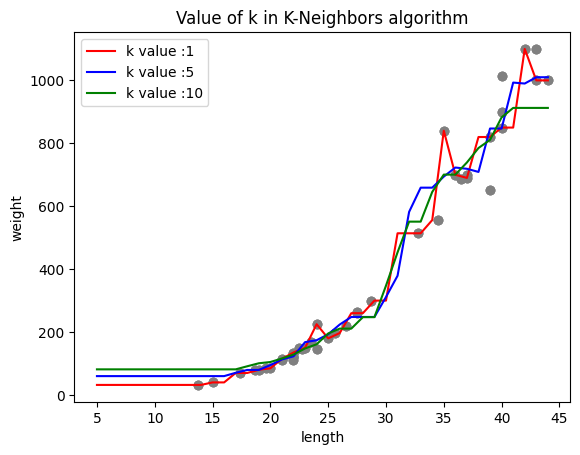
다음과 같은 그래프가 그려진다.
(분류문제에서는 동률을 막기 위해 홀수로 k값을 준다고 하나, 여기서는 회귀문제라 10을 준 것 같다.)
k값이 늘어남에 따라 예측값이 어떻게 변하는 지를 알 수 있다.
k값이 작을수록 과적합(overfitting) 문제를 야기할 수 있고, 또 k값이 커질수록 데이터 포인트들 사이의 세부적인 경계를 감지하기 어렵게 만들 수 있다.
좀 더 확실한 비교를 위해 그래프 3가지를 하나의 그래프로 표현하면 다음과 같다.
k값이 1인 빨간선은 그래프가 날카롭고 10인 초록선은 뭉툭한 모습을 보여준다.
선택미션
| 주차 | 진도 | 선택 미션 |
| 2주차 (07/10 ~ 16) |
chapter03 | 모델 파라미터에 대해 설명하기 |
모델 파라미터 설명하기
모델 파라미터는 기계학습 모델에서 학습되는 가중치(weight)와 편향(bias) 값들을 의미한다.
이러한 파라미터들은 모델이 데이터를 학습하고 예측을 수행하는 데 사용된다.
간단한 예시로 입력 변수(x)와 출력변수(y)의 선형관계를 표현한 1차 회귀식(단순회귀식) 모형이 있다고 가정해보자.
y=wx+b
- y는 출력 변수
- x는 입력 변수
- w 가중치(weight)로서 x의 영향력
- b는 편향(bias) 혹은 상수로서 y의 절편
여기서 w와 b가 모델 파라미터이다. 이 모델을 학습시키기 위해서 주어진 학습 데이터에서 w와 b값을 조정해야한다.
머신러닝에서는 이 파라미터 값을 학습 과정에서 최적화하여 조정된다.
2023.07.18 - [스터디/혼공학습단 - 머신러닝+딥러닝] - [혼공학습단] 다른 회귀분석 모델을 써보자
[혼공학습단] 다른 회귀분석 모델을 써보자
배경 chapter 3까지 공부하면서 회귀모델 두 가지를 공부했다. 하지만 scikit-learn는 아직 써보지 못한 Regressor가 많이 남았다. 다른 회귀모델을 써보면서 직접 점수까지 확인해보기로 했다. 상세 먼
jinooh.tistory.com
'스터디 > 혼공학습단 10기 - 자바 & 머신러닝' 카테고리의 다른 글
| [혼공학습단] 객체지향 프로그래밍을 좀 더 쉽게 이해해보자. (0) | 2023.07.16 |
|---|---|
| [혼공학습단] - 혼공자바 2주차(7/10 ~ 7/16) (0) | 2023.07.16 |
| [혼공학습단] Java - print() 메서드 종류 (0) | 2023.07.09 |
| [혼공학습단] - 혼공자바 1주차(7/3 ~ 7/9) (0) | 2023.07.05 |
| [혼공학습단] 자바와 파이썬은 무엇이 달라요? (0) | 2023.07.03 |




댓글